PMD Source Code Reading (2) — Copy and Paste Detection
This article introduces the principles of CPD code copy-paste detection, a method that can be used for detecting copy-pasting in any text.
Introduction
This article introduces the principles of CPD (Copy-Paste-Detector) code copy-paste detection, which can be used for detecting copy-pasting in any text.
CPD is part of PMD and is used to find duplicate code snippets in a project. The main idea is to use a tokenizer to break the code into individual words, transforming the problem of detecting duplicate code into a string matching problem, which is then solved using the Rabin-Karp algorithm.
CPD Implementation Principles
Note: The version of PMD studied in this article is 5.5.2, and the tool used to automatically generate class diagrams from code is the Eclipse plugin ModelGoon.
Most of the CPD code is located in the net.sourceforge.pmd.cpd package of the subproject pmd-core, and there are also two Java files in the net.sourceforge.pmd.cpd package of various language subprojects.
CPD can be started in various ways, including Ant, GUI, CommandLine, etc. Here we choose the simplest method to execute it from the command line, with the program entry being the Main method of CPDCommandLineInterface.
In the CPDListener interface, the entire process is divided into five parts: Init, Hash, Match, Grouping, Done. This division is for the convenience of Benchmarking the execution time of each phase. To facilitate understanding of the CPD process, we will redefine it into six parts: Initialization, Reading Code, Tokenization, String Matching, Processing Candidate Results, Result Display.
1. Initialization
In the initialization phase, CPD uses JCommander to read and parse command line parameters. Optional parameters can be seen in CPDConfiguration, with the main parameters being: *minimumTileSize (minimal tokens): The minimum number of tokens required for duplication; if the number of duplicate tokens in two code segments is greater than or equal to this value, they are considered to be copy-pasted. *files: File paths, defaults to recursively searching for code files. *language: Language, defaults to Java. *encoding: Code file encoding, defaults to the local default encoding. *render: The output method for matching results, defaults to simple string output. *ignore-literals, ignore-identifiers, etc.: Ignore literals, identifiers, etc. during the tokenization process.
2. Reading Files
CPD recursively reads all code files in the specified directory by default. How does CPD know the file extensions of code files? As mentioned earlier, PMD uses Java's SPI mechanism to connect pmd-core with other subprojects. Taking Java as the default language, the content of the src/main/resources/META-INF/services/net.sourceforge.pmd.cpd.Language file in the pmd-java project is net.sourceforge.pmd.cpd.JavaLanguage, and the JavaLanguage class code is as follows:
package net.sourceforge.pmd.cpd;
import java.util.Properties;
public class JavaLanguage extends AbstractLanguage {
public JavaLanguage() {
this(System.getProperties());
}
public JavaLanguage(Properties properties) {
super("Java", "java", new JavaTokenizer(), ".java");
setProperties(properties);
}
public final void setProperties(Properties properties) {
JavaTokenizer tokenizer = (JavaTokenizer) getTokenizer();
tokenizer.setProperties(properties);
}
}package net.sourceforge.pmd.cpd;
import java.util.Properties;
public class JavaLanguage extends AbstractLanguage {
public JavaLanguage() {
this(System.getProperties());
}
public JavaLanguage(Properties properties) {
super("Java", "java", new JavaTokenizer(), ".java");
setProperties(properties);
}
public final void setProperties(Properties properties) {
JavaTokenizer tokenizer = (JavaTokenizer) getTokenizer();
tokenizer.setProperties(properties);
}
}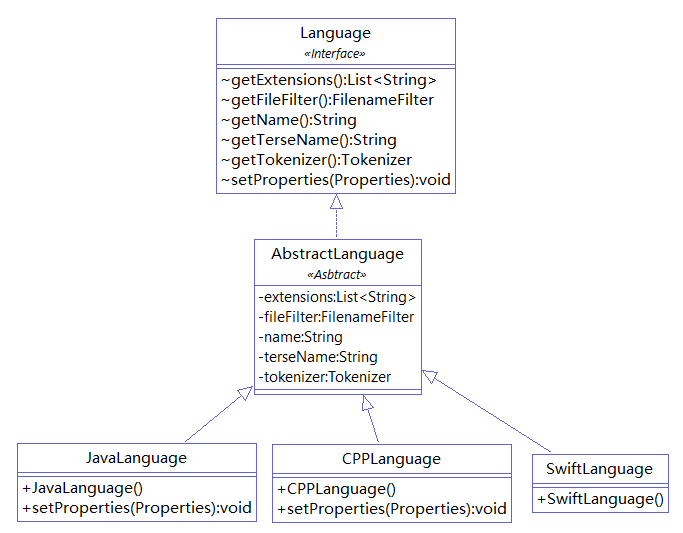
In the net.sourceforge.pmd.cpd.LanguageFactory class of pmd-core, CPD uses ServiceLoader to obtain all supported language implementations of Language and retrieves a specific Language instance through parameters.
private LanguageFactory() {
ServiceLoader<Language> languageLoader = ServiceLoader.load(Language.class);
Iterator<Language> iterator = languageLoader.iterator();
while (iterator.hasNext()) {
try {
Language language = iterator.next();
languages.put(language.getTerseName().toLowerCase(), language);
} catch (UnsupportedClassVersionError e) {
System.err.println("Ignoring language for CPD: " + e.toString());
}
}
}private LanguageFactory() {
ServiceLoader<Language> languageLoader = ServiceLoader.load(Language.class);
Iterator<Language> iterator = languageLoader.iterator();
while (iterator.hasNext()) {
try {
Language language = iterator.next();
languages.put(language.getTerseName().toLowerCase(), language);
} catch (UnsupportedClassVersionError e) {
System.err.println("Ignoring language for CPD: " + e.toString());
}
}
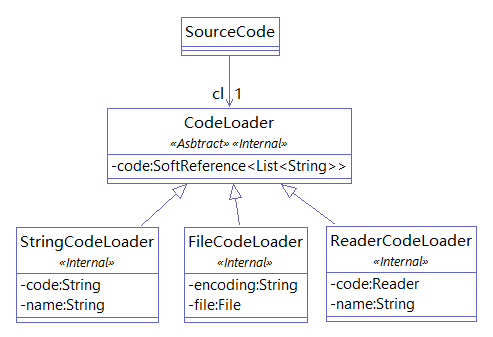
}CPD reads code from SourceCode. SourceCode holds a CodeLoader instance for reading code; SourceCode itself does not store code but retrieves it from CodeLoader when needed.
CodeLoader has three implementations to wrap String, File, and Reader, providing a unified Reader format to the load method of CodeLoader. CodeLoader uses SoftReference<List
CPD reads files in local encoding by default, but even if a file encoding is specified in the parameters, CPD will still check the BOM information of the file. If the file has a BOM marker, it will use the encoding indicated by the BOM. (BOM: Byte Order Mark, three invisible characters at the beginning of the file, typically used to mark files encoded in UTF-8, UTF-16, UTF-32).
BOMInputStream inputStream = new BOMInputStream(new FileInputStream(file), ByteOrderMark.UTF_8,
ByteOrderMark.UTF_16BE, ByteOrderMark.UTF_16LE);
if (inputStream.hasBOM()) {
encoding = inputStream.getBOMCharsetName();
}BOMInputStream inputStream = new BOMInputStream(new FileInputStream(file), ByteOrderMark.UTF_8,
ByteOrderMark.UTF_16BE, ByteOrderMark.UTF_16LE);
if (inputStream.hasBOM()) {
encoding = inputStream.getBOMCharsetName();
}3. Tokenization
In the tokenization phase, CPD uses a tokenizer to split the read code into individual words (tokens). Each language's subproject contains a net.sourceforge.pmd.cpd package with *Tokenizer.java files that serve as the Tokenizer for that language. During the code reading phase, CPD obtains the JavaLanguage instance through the SPI mechanism, and in the tokenization phase, it can directly retrieve the JavaTokenizer from JavaLanguage.
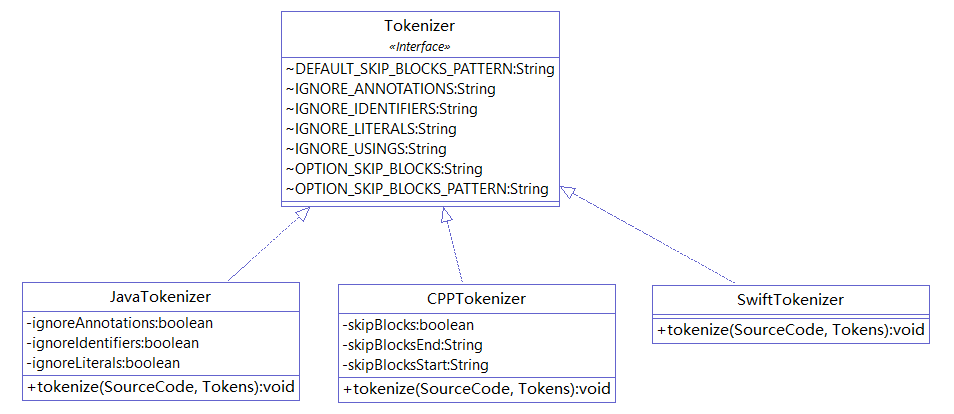
The tokenizers in PMD are provided by JavaCC or Antlr. Here we will explain using Antlr as an example. Antlr provides syntax description files for multiple languages (https://github.com/antlr/grammars-v4), and processing these syntax description files with Antlr yields the corresponding language's lexer, allowing for tokenization.
For example, the following code:
public class Hello{
public static void main(String[] args){
System.out.println("Hello, world!");
}public class Hello{
public static void main(String[] args){
System.out.println("Hello, world!");
}The result of the tokenization operation is:
public
class
Hello
{
public
static
void
main
(
String
[
]
args
)
{
System
.
out
.
println
(
"Hello, world!"
)
;
}
<EOF>public
class
Hello
{
public
static
void
main
(
String
[
]
args
)
{
System
.
out
.
println
(
"Hello, world!"
)
;
}
<EOF>Additionally, we can obtain the type of each word (the type is related to the syntax description file and varies by language).
| Token | Type |
|---|---|
| public | PUBLIC |
| class | CLASS |
| Hello | Identifier |
| { | LBRACE |
| ... | ... |
The type of the words is used to remove specific types of words. For example, if the parameter ignore-identifiers is set to true in the initialization phase, CPD will remove Identifier type words from the tokenization results, such as Hello in the table above.
4. String Matching
The inputs required for this phase are: *minimumTileSize: The minimum number of duplicate tokens (input from the initialization phase), type int. *sourceCode: The read code (output from the code reading phase), type Map<String, SourceCode>. *tokens: The list of words (output from the tokenization phase, all tokenization results of the code are aggregated), type Tokens.
Several entity classes involved in this phase: *TokenEntry: Represents a Token, storing the file (tokenSrcID) where a Token is located, the starting line (beginLine), and the identifier (i.e., the encoding mapped during the Hash phase of the Rabin-Karp algorithm). CPD uses HashMap for encoding; for example, for the string ABA, each letter is stored in HashMap sequentially, checking if the letter already exists each time. If it exists, it assigns the previous count; if not, it increments the count by 1. *Mark: Represents a code snippet, holding a TokenEntry as the starting Token of a piece of code and recording the number of lines and content of that code. *Match: Represents the matching result; Match uses Set to contain multiple code snippets (Marks) that are considered to have the same content, and it also records the number of duplicate Tokens in these code snippets.
Assuming there are two files, Hello1.java and Hello2.java, with contents public class Hello1{} and public class Hello2{} respectively, then sourceCode can be simply represented as:
["Hello1.java", "public class Hello1{}"], ["Hello2.java", "public class Hello2{}"]
tokens can be simply represented as:
["public", "class", "Hello1", "{", "}", "
We use | to represent the end of a file (EOF) and letters like A, B, C, etc., to represent words (Tokens). The problem can be represented as: Given EABCDEDA and IJABCDEFG, find the duplicate substrings in the two strings, with a substring length greater than or equal to 3 (i.e., set minimumTileSize to 3). The obvious answer is ABCD and BCD, but in this problem, BCD is to be discarded.
In this example, tokens are EABCDEDA | IJABCDEFG. CPD's idea is to first find duplicate substrings of length 3. Suppose there is a row of boxes; CPD starts from the end of the file, storing a string of length 3 in a box each time, with identical strings placed in the same box.
| EFG | DEF | CDE | BCD , BCD | ABC , ABC | JAB | IJA | EDA | DED | ...... |
CPD uses HashMap as these "boxes". Since comparing two strings requires character-by-character comparison, which is time-consuming, numerical comparisons can be done in one go. Therefore, CPD uses hash values as the basis for comparing character (Token) strings. Marking A, B, C ... Z as 0, 1, 2 ... 25, assuming the string length is n, let M = 26, the hash value of the string can be calculated as:
The mapping value of the 1st letter * M ^ (n-1) + The mapping value of the 2nd letter * M ^ (n-2) + ... + The mapping value of the nth letter * M ^ (n-n)
The hash value of ABC is 0 * 26 * 26 + 1 * 26 + 2
The hash value of BCD is 1 * 26 * 26 + 2 * 26 + 3
It can be seen that marking all different characters (Tokens) from 0 to k ensures that as long as M >= k + 1, different character (Token) strings will have different hash values. However, we do not know how many characters (Tokens) there will be, and taking a very large value for M will affect computation speed. Therefore, we choose a suitable value (CPD uses 37, because z = 37 * x can be split into y = x + 8 * x; z = x + 4 * y, both steps correspond to a LEA x86 instruction, which is fast to compute), and for potential hash collisions, we will handle them further.
Additionally, CPD uses the Rabin-Karp algorithm to overcome the "forgetfulness" of naive string matching algorithms. Some information from the previous match can actually be applied to the next match, while naive string matching algorithms simply discard this information and start over, wasting time. The Rabin-Karp algorithm utilizes this information to improve runtime speed.
For example, searching for "CDE" in the string "ABCDE": The naive string matching algorithm independently calculates the hash values of the three strings being checked:
The hash value of ABC is 0 * 26 * 26 + 1 * 26 + 2 = value1
The hash value of BCD is 1 * 26 * 26 + 2 * 26 + 3 = value2
The hash value of CDE is 2 * 26 * 26 + 3 * 26 + 4 = value3
In contrast, the Rabin-Karp algorithm builds on the previous match, removing the information of the deleted letter and adding the information of the newly added letter:
The hash value of ABC is 0 * 26 * 26 + 1 * 26 + 2 = value1
The hash value of BCD is (value1 - 0 * 26 * 26) * 26 + 3 = value2
The hash value of CDE is (value2 - 1 * 26 * 26) * 26 + 4 = value3
When the string to be matched is long, the Rabin-Karp algorithm can utilize information from the previous match to reduce the computation required for the next match, resulting in a significant speed improvement.
Continuing with the string matching example, after the string matching phase, the candidate results obtained are:
|EFG|DEF|CDE|EDA,BCD,BCD|ABC,ABC|JAB|IJA|DED|......|
After two hashes using the Rabin-Karp algorithm and HashMap, hash collisions may occur; for example, EDA and BCD may have the same hash value after the two hashes.
5. Processing Candidate Results
CPD compares each substring in the boxes pairwise:
- Substrings have the same leading letter, such as BCD, BCD in the example.
- The number of identical letters in the substrings is less than the specified minimum, indicating a hash collision, such as EDA, BCD in the example.
- The two code snippets overlap.
After excluding the above three cases, CPD calculates the actual number of duplicate tokens in these code snippets (Marks) and places the code snippets (Marks) with duplicate token counts into the same Match, thus obtaining accurate results.
|ABCD,ABCD|
6. Result Display
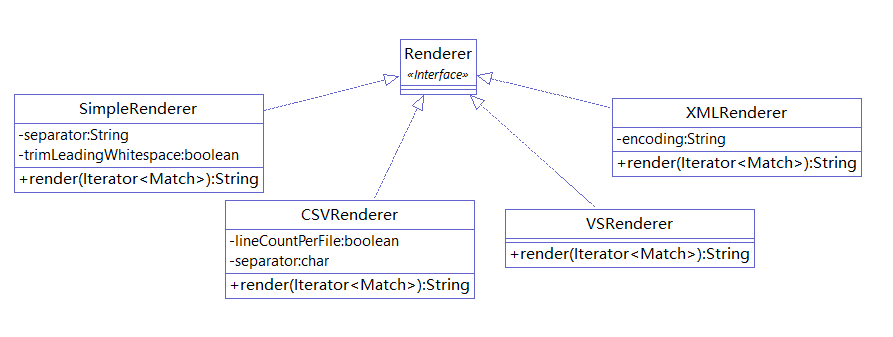
CPD provides various ways to display results, with the default being to use SimpleRenderer to print the results directly to the console.
Conclusion
This article introduced the principles of CPD code copy-paste detection. Besides the Java copy-paste detection discussed in the article, using the syntax description files provided by Antlr, copy-paste detection can be implemented for most programming languages. The method introduced in this article can be further extended to detect copy-pasting in any text.
Comments
No comments yet. Be the first to comment!