LMAX Disruptor 介绍:高性能线程间通信框架
LMAX Disruptor 是一个专为高并发、低延迟场景设计的开源线程间通信框架。本文介绍其核心概念和设计原理,对比 Java 内置队列的性能瓶颈,解释环形缓冲区、无锁设计和缓存行填充等关键技术,帮助理解其高性能实现原理。
1. 背景:为何需要 Disruptor?
Disruptor 由英国的外汇交易公司 LMAX 开发,其初衷是为了解决内存队列在高并发场景下的延迟问题。 传统的基于锁的队列在多线程环境下会因锁竞争导致显著的性能瓶颈和延迟抖动。LMAX 的团队在构建高性能金融交易平台时发现,队列操作的延迟甚至可以与 I/O 操作相媲美。
基于这一痛点,Disruptor 应运而生。它是一个高性能的线程间通信队列,专注于解决线程间通信的效率问题,而非像 Kafka 那样的进程间通信。 凭借其出色的设计,基于 Disruptor 的系统,单个线程每秒能够处理高达 600 万订单。 这一成就使其在 2010 年的 QCon 大会上一举成名,并获得了企业应用软件专家 Martin Fowler 的专门撰文介绍以及 Oracle 官方的 Duke 大奖。 如今,包括 Apache Storm、Camel、Log4j 2 和 HBase 在内的许多知名项目都已采用 Disruptor 来提升性能。
2. Disruptor 简介
从用途上看,Disruptor 与 Java 内置的BlockingQueue类似,都是用于在线程间传递数据。 然而,Disruptor 拥有一些独特的特性,使其在性能上遥遥领先:
- 多播给消费者: 同一个事件可以被多个消费者处理,且消费者之间可以并行执行,也可以形成依赖关系。
- 提前申请内存: Disruptor 中的所有事件对象都在启动时预先分配,避免了运行时的动态内存分配和垃圾回收(GC)带来的停顿。
- 可选的无锁设计: 在单生产者场景下,Disruptor 可以完全避免使用锁,从而消除锁竞争带来的开销。
3. 核心概念
要理解 Disruptor 的工作原理,首先需要了解其几个核心概念:
- Ring Buffer (环形缓冲区): 这是 Disruptor 的核心数据结构,一个预先分配好大小的数组。由于是数组,其在内存中的连续性对 CPU 缓存非常友好。
- Sequence (序号): 每个生产者和消费者都维护着自己的序号,用于追踪其处理进度。序号是保证线程间正确传递数据的关键。
Sequence对象内部通过缓存行填充(Cache Line Padding)来避免伪共享问题。 - Sequencer (序号生成器): Disruptor 的核心,负责在生产者和消费者之间快速、正确地传递数据。它有两个实现:
SingleProducer(单生产者)和MultiProducer(多生产者),均为并行算法。 - Sequence Barrier (序号屏障): 由
Sequencer创建,用于协调消费者之间的依赖关系,并决定消费者可以消费哪些数据。 - Wait Strategy (等待策略): 当消费者速度快于生产者时,消费者需要等待新的事件。等待策略定义了消费者如何等待,例如可以通过
BlockingWaitStrategy(加锁)、SleepingWaitStrategy(休眠)、YieldingWaitStrategy(让出 CPU)或BusySpinWaitStrategy(忙等)等方式。 - Event (事件): 在 Disruptor 中流动的数据单元。它是一个由用户定义的普通 Java 对象。
- EventProcessor (事件处理器): 处理事件的主要循环,它会持续监控 Ring Buffer 中的新事件并进行处理。
BatchEventProcessor是其主要实现。 - EventHandler (事件处理句柄): 用户实现的接口,代表了消费者的具体业务逻辑。
- Producer (生产者): 负责向 Disruptor 发布事件的线程。
下图展示了这些组件是如何协同工作的:
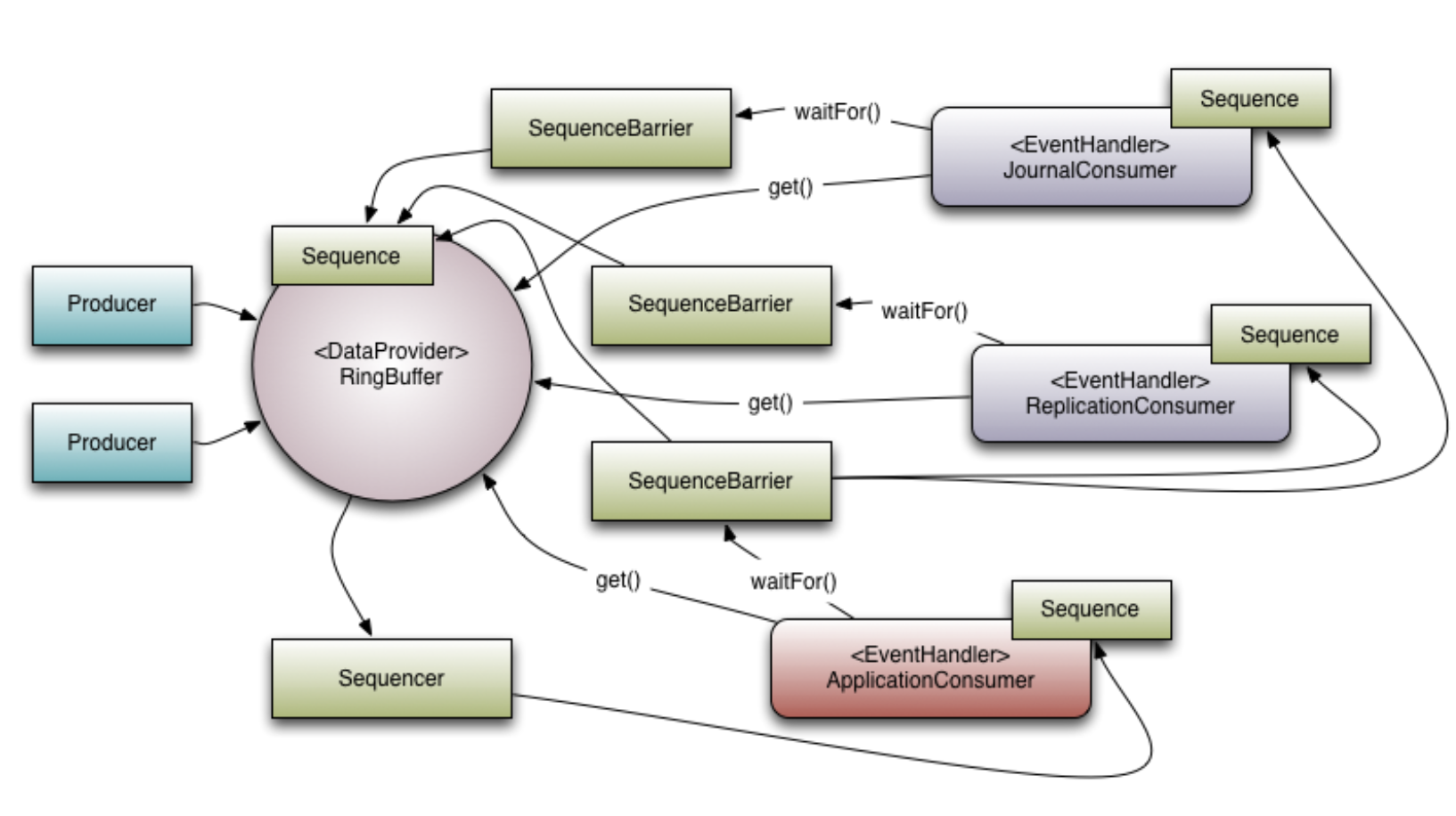
4. 与 Java 内置队列的对比及性能瓶颈分析
为了更深入地理解 Disruptor 的优势,我们将其与 Java 中常用的ArrayBlockingQueue进行对比。
4.1 Java 内置队列概览
| 队列 | 有界性 | 锁 | 数据结构 |
|---|---|---|---|
ArrayBlockingQueue | bounded | 加锁 | arraylist |
LinkedBlockingQueue | optionally-bounded | 加锁 | linkedlist |
ConcurrentLinkedQueue | unbounded | 无锁 | linkedlist |
LinkedTransferQueue | unbounded | 无锁 | linkedlist |
PriorityBlockingQueue | unbounded | 加锁 | heap |
DelayQueue | unbounded | unbounded | heap |
ArrayBlockingQueue是一个典型的基于数组的有界队列,通过加锁来保证线程安全。而ConcurrentLinkedQueue等无锁队列虽然性能更高,但它们是无界的,在生产者速度远快于消费者的场景下,可能会导致内存溢出。因此,在需要有界队列且关注性能的场景下,ArrayBlocking-Queue常常是备选方案。然而,它存在以下性能瓶颈:
4.2 加锁 (Locking)
加锁是ArrayBlockingQueue最主要的性能瓶颈。线程会因为竞争锁而被挂起和恢复,这个过程会产生巨大的上下文切换开销。如果持有锁的线程发生缺页错误或被调度器延迟,所有等待该锁的线程都将停滞不前,严重影响系统吞吐量。
实验对比:
一个简单的实验可以直观地展示锁的开销。对一个 64 位的计数器循环自增 5 亿次:
| Method | Time (ms) |
|---|---|
| Single thread | 300 |
| Single thread with CAS | 5,700 |
| Single thread with lock | 10,000 |
| Single thread with volatile write | 4,700 |
| Two threads with CAS | 30,000 |
| Two threads with lock | 224,000 |
从数据可以看出,无论是单线程还是多线程,加锁的性能都是最差的。在多线程场景下,使用 CAS(Compare-And-Swap,比较并交换)的性能远优于加锁。
锁与 CAS 的区别:
- 锁 (Locking):一种悲观策略,假定总会有冲突发生,所以在访问共享资源前先加锁,形成一个临界区,只允许一个线程进入。
ArrayBlockingQueue的offer方法就是通过ReentrantLock来实现的。 - 原子变量 (Atomic Variables) / CAS: 一种乐观策略,假定没有冲突。线程直接尝试修改数据,通过 CPU 级别的原子指令(CAS)来保证操作的原子性。如果操作期间数据被其他线程修改,CAS 操作会失败,此时线程通常会通过自旋等方式重试,直到成功。
在竞争不激烈的情况下,CAS 的性能通常优于锁。但在高竞争环境下,大量线程的 CAS 自旋重试也可能消耗大量 CPU 资源。然而,在真实世界的多数场景下,原子变量的性能表现通常优于锁,并且不会产生死锁等活性问题。
4.3 伪共享 (False Sharing)
这是另一个影响性能的关键因素,但常常被忽略。现代 CPU 为了提高性能,都有多级缓存(L1, L2, L3)。数据在主存和 CPU 缓存之间是以**缓存行(Cache Line)**为单位进行传输的,一个缓存行通常是 64 字节。
当一个 CPU 核心修改了其缓存中的某个缓存行的数据时,为了保证数据一致性,其他 CPU 核心中相同的缓存行副本必须被标记为“失效”(Invalidated)。这意味着其他核心下次需要访问该缓存行中的任何数据时,都必须重新从主存中加载,这个过程会带来显著的性能开销。
伪共享就发生在这里:如果多个线程修改的变量虽然在逻辑上是独立的,但物理上却位于同一个缓存行中,那么一个线程对其中一个变量的修改就会导致其他线程的缓存行失效,即使它们操作的是不同的变量。
ArrayBlockingQueue中有三个关键的成员变量:takeIndex (消费者指针), putIndex (生产者指针), 和 count (队列中元素数量)。这三个变量很可能被分配在同一个缓存行中。当生产者put一个元素时,会修改putIndex和count;当消费者take一个元素时,会修改takeIndex和count。这种操作模式会导致生产者和消费者线程之间频繁地使对方的缓存行失效,造成严重的性能下降。
解决方案:缓存行填充
解决伪共享的常用方法是缓存行填充 (Cache Line Padding)。通过在需要隔离的变量前后填充一些无用数据,强制将这些变量分配到不同的缓存行中,从而避免它们之间的相互影响。
在 JDK 8 之后,Java 官方提供了@Contended注解来帮助开发者更优雅地解决伪共享问题,它会自动进行缓存行填充。
5. Disruptor 的设计方案:追求极致性能
Disruptor 通过一系列精巧的设计来克服传统队列的性能瓶颈。
-
环形数组结构: 采用数组而非链表,以利用其内存连续性,这对 CPU 缓存极为友好。所有事件对象都在初始化时一次性创建并放入 Ring Buffer,实现了对象的复用,极大地减少了 GC 压力。
-
元素位置定位:
- Ring Buffer 的长度被设计为 2 的 n 次方,这样就可以通过位运算(
sequence & (bufferSize - 1))来代替取模运算(sequence % bufferSize)快速定位元素位置,效率更高。 - 索引(
sequence)使用long类型,即使以每秒百万 QPS 的速度处理,也需要数十万年才会溢出,无需担心索引溢出问题。
- Ring Buffer 的长度被设计为 2 的 n 次方,这样就可以通过位运算(
-
无锁设计:
- 单生产者场景: 在单生产者模式下,生产者可以无锁地申请写入空间。因为它自己是唯一的写入者,所以它知道下一个可用的位置,无需与其他线程竞争。
- 多生产者场景: 在多生产者场景下,Disruptor 使用 CAS 来保证线程安全地申请写入空间。每个生产者线程会尝试通过 CAS 操作来“声明”自己将要使用的序号区间。
- 消费者: 消费者通过追踪生产者的序号以及它所依赖的其他消费者的序号,来确定哪些数据是可读的,这个过程同样是无锁的。
-
通过 Sequence 解决伪共享: Disruptor 中的核心状态,如生产者的
cursor和消费者的sequence,都被封装在Sequence对象中。这个对象内部就使用了缓存行填充技术,在核心的value字段前后填充了多个long类型的无用变量,确保了每个Sequence对象都独占一个或多个缓存行,从根本上避免了伪共享问题。 -
对象头与内存布局: Disruptor 的设计也充分考虑了 JVM 的对象内存布局。一个 Java 对象在内存中由对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)组成。 对象头包含了 Mark Word(用于存储哈希码、GC 信息、锁信息等)和类型指针。 通过精巧的缓存行填充,Disruptor 能确保其核心的
Sequence值在加载到 CPU 缓存时,不会与其他可能被修改的数据位于同一个缓存行,保证了性能。
6. 结论
Disruptor 通过对底层硬件工作原理的深刻理解,实现了一系列极致的性能优化。 它通过环形数组、无锁 CAS、缓存行填充等技术,有效地解决了传统队列在并发场景下的锁竞争和伪共享问题,提供了极高的吞吐量和极低的延迟。 虽然其使用方式相比 Java 内置队列要复杂一些,但在对性能有严苛要求的系统中,Disruptor 无疑是一个值得考虑的强大工具。
评论
暂无评论,来发表第一条评论吧