PMD 源码阅读(2)— 复制粘贴检测
本文介绍了 CPD 代码复制粘贴检测的原理,该方法可以用于任意文本的复制粘贴检测。
前言
本文介绍了 CPD 代码复制粘贴检测的原理,该方法可以用于任意文本的复制粘贴检测。
CPD(Copy-Paste-Detector)是 PMD 的一部分,用于查找项目中重复的代码片段。其主要思想是使用分词器(Tokenizer)将代码分解成一个个单词,将重复代码检测问题转换成字符串匹配问题,然后 Rabin-Karp 算法进行求解。
CPD 实现原理
注:本文研究的 PMD 版本是 5.5.2 ,使用的根据代码自动生成类图的工具为 Eclipse 插件 ModelGoon。
CPD 的大部分代码在子项目 pmd-core 的 net.sourceforge.pmd.cpd 包下,另外在各个语言的子项目的 net.sourceforge.pmd.cpd 包下也有两个 Java 文件。
CPD 有多种启动方式,包括 Ant 、GUI 、CommandLine 等,我们这里选择最简单的从命令行开始执行,程序入口为 CPDCommandLineInterface 的 Main 方法。
在接口 CPDListener 中可以看到整个过程被划分为了 Init 、Hash 、Match 、Grouping 、Done 五个部分,这是为了方便 Benchmark 统计各个阶段的执行时间。为了方便理解 CPD 的流程,我们将其重新划分为六个部分:初始化、读取代码、分词、字符串匹配、处理候选结果、结果展示。
1. 初始化
初始化阶段,CPD 使用 JCommander 进行命令行参数的读取和解析。可选的参数可以在 CPDConfiguration 中看到,主要的参数有
*minimumTileSize(minimal tokens):最小重复的 token 数量,两段代码重复的 token 数量大于等于该值时,被认为是复制粘贴。
*files:文件路径,默认递归查找代码文件
*language:语言,默认为 Java
*encdoing:代码文件编码,默认为本机默认编码
*render:匹配结果的输出方式,默认为简单的字符串输出
*ignore-literals 、 ignore-identifiers 等:在分词过程中忽略字面量、标识符等
2. 读取文件
CPD 默认递归地读取指定目录下的所有代码文件。CPD 是如何知道代码文件的扩展名的呢?之前说过,PMD 通过 Java 的 SPI 机制将 pmd-core 与其他子项目进行联系的。以默认语言 Java 为例,pmd-java 项目的 src/main/resources/META-INF/services/net.sourceforge.pmd.cpd.Language 文件内容为 net.sourceforge.pmd.cpd.JavaLanguage ,JavaLanguage 类代码如下:
package net.sourceforge.pmd.cpd;
import java.util.Properties;
public class JavaLanguage extends AbstractLanguage {
public JavaLanguage() {
this(System.getProperties());
}
public JavaLanguage(Properties properties) {
super("Java", "java", new JavaTokenizer(), ".java");
setProperties(properties);
}
public final void setProperties(Properties properties) {
JavaTokenizer tokenizer = (JavaTokenizer) getTokenizer();
tokenizer.setProperties(properties);
}
}package net.sourceforge.pmd.cpd;
import java.util.Properties;
public class JavaLanguage extends AbstractLanguage {
public JavaLanguage() {
this(System.getProperties());
}
public JavaLanguage(Properties properties) {
super("Java", "java", new JavaTokenizer(), ".java");
setProperties(properties);
}
public final void setProperties(Properties properties) {
JavaTokenizer tokenizer = (JavaTokenizer) getTokenizer();
tokenizer.setProperties(properties);
}
}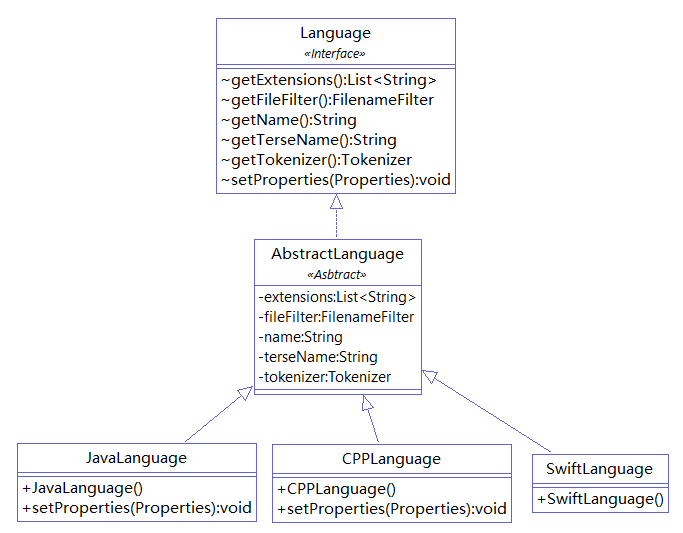
在 pmd-core 的 net.sourceforge.pmd.cpd.LanguageFactory 类中,CPD 使用 ServiceLoader 获取所有支持的语言对 Language 的实现,并通过参数获取特定的一个 Language 实例。
private LanguageFactory() {
ServiceLoader<Language> languageLoader = ServiceLoader.load(Language.class);
Iterator<Language> iterator = languageLoader.iterator();
while (iterator.hasNext()) {
try {
Language language = iterator.next();
languages.put(language.getTerseName().toLowerCase(), language);
} catch (UnsupportedClassVersionError e) {
System.err.println("Ignoring language for CPD: " + e.toString());
}
}
}private LanguageFactory() {
ServiceLoader<Language> languageLoader = ServiceLoader.load(Language.class);
Iterator<Language> iterator = languageLoader.iterator();
while (iterator.hasNext()) {
try {
Language language = iterator.next();
languages.put(language.getTerseName().toLowerCase(), language);
} catch (UnsupportedClassVersionError e) {
System.err.println("Ignoring language for CPD: " + e.toString());
}
}
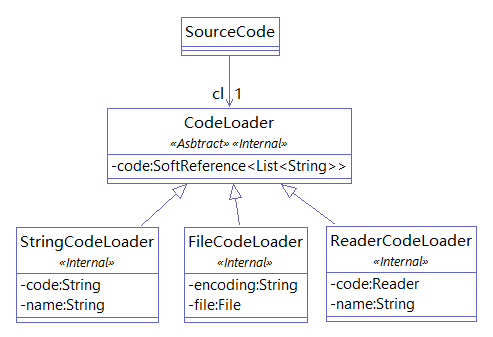
}CPD 从 SourceCode 中读取代码。SourceCode 持有一个 CodeLoader 实例用于读取代码, SourceCode 本身不存储代码,只是在需要获取代码时从 CodeLoader 中获取。
CodeLoader 有三种实现,用于将 String 、File 、Reader 进行包装,统一以 Reader 的形式提供给 CodeLoader 的 load 方法。CodeLoader 使用 SoftReference<List
CPD 默认以本地编码读取文件,但即使是在参数中指定了文件编码,CPD 还是会检查文件的 BOM 信息,如果文件存在 BOM 标记,则以 BOM 的编码为准。(BOM:字节顺序标记,byte-order mark,文件开头三个不可见的字符,它通常被用来标记 UTF-8 、UTF-16 、UTF-32 编码的文件)。
BOMInputStream inputStream = new BOMInputStream(new FileInputStream(file), ByteOrderMark.UTF_8,
ByteOrderMark.UTF_16BE, ByteOrderMark.UTF_16LE);
if (inputStream.hasBOM()) {
encoding = inputStream.getBOMCharsetName();
}BOMInputStream inputStream = new BOMInputStream(new FileInputStream(file), ByteOrderMark.UTF_8,
ByteOrderMark.UTF_16BE, ByteOrderMark.UTF_16LE);
if (inputStream.hasBOM()) {
encoding = inputStream.getBOMCharsetName();
}3. 分词
在分词阶段,CPD 使用分词器(Tokenizer)将已读取的代码拆分成一个个单词(token)。每个语言的子项目的 net.sourceforge.pmd.cpd 包下的 *Tokenizer.java 就是各个语言的 Tokenizer。在读取代码阶段,CPD 通过 SPI 机制获取了 JavaLanguage 实例,在分词阶段就可以直接从 JavaLanguage 中获取 JavaTokenizer。
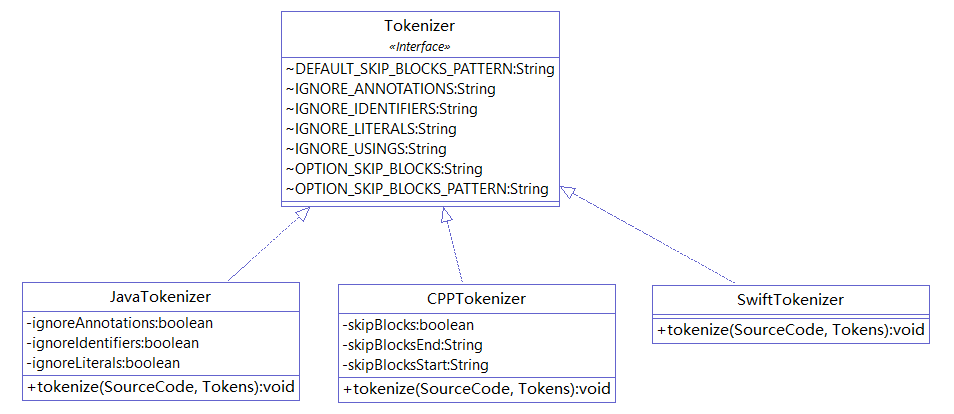
PMD 中的分词器由 JavaCC 或 Antlr 提供,我们这里以 Antlr 为例进行说明。Antlr 提供了多种语言的语法描述文件( https://github.com/antlr/grammars-v4 ), 使用 Antlr 对语法描述文件进行处理,就可以得到相应语言的词法分析器,从而进行分词。
如下面的一段代码:
opublic class Hello{
opublic static void main(String[] args){
oSystem.out.println("Hello, world!");
o}opublic class Hello{
opublic static void main(String[] args){
oSystem.out.println("Hello, world!");
o}分词操作的结果为
public
class
Hello
{
public
static
void
main
(
String
[
]
args
)
{
System
.
out
.
println
(
"Hello, world!"
)
;
}
<EOF>public
class
Hello
{
public
static
void
main
(
String
[
]
args
)
{
System
.
out
.
println
(
"Hello, world!"
)
;
}
<EOF>此外,我们还可以获得各个单词的类型(类型与语法描述文件有关,因语言而异)。
| Token | Type |
|---|---|
| public | PUBLIC |
| class | CLASS |
| Hello | Identifier |
| { | LBRACE |
| ... | ... |
单词的类型用于去掉特定类型的单词。例如在初始化阶段将参数 ignore-identifiers 设置为 true ,那么 CPD 将从分词的结果中去掉 Identifier 类型的单词,比如上表中的 Hello。
4. 字符串匹配
该阶段需要的输入:
*minimumTileSize:最小重复的 token 数量(初始化阶段的输入),类型为 int。
*sourceCode:读取的代码(读取代码阶段的输出),类型为 Map<String,SourceCode>。
*tokens:单词列表(分词阶段的输出,所有代码的分词结果被汇聚到了一起),类型为 Tokens。
该阶段涉及的几个实体类:
*TokenEntry:代表一个 Token,保存了一个 Token 所在文件(tokenSrcID)、起始行(beginLine)以及 identifier(即 Rabin-Karp 算法的 Hash 阶段映射的编码)。CPD 使用 HashMap 进行编码,例如对字符串 ABA ,将每个字母依次存入 HashMap ,每次存储时先检查字母是否已经存在,如果存在则赋予之前的计数,如果不存在则计数加 1。
*Mark:代表一个代码片段,它持有一个 TokenEntry 作为一段代码的起始 Token,并记录了这段代码的行数以及内容。
*Match:代表匹配的结果,Match 使用 Set<Mark> 包含了多个代码片段(Mark),这些代码片段的内容被认为是相同的,此外还记录了这些代码片段重复的 Token 个数。
假设有 Hello1.java 和 Hello2.java 两个文件,内容分别为 public class Hello1{} 和 public class Hello2{}
那么 sourceCode 可以简单表示为
["Hello1.java","public class Hello1{}"] , ["Hello2.java","public class Hello2{}"]
tokens 可以简单地表示为:
["public","class","Hello1","{","}","
我们使用|表示文件结尾(EOF),使用 A 、B 、C 等字母表示单词(Token),问题可以表示为: 有 EABCDEDA 和 IJABCDEFG 两个字符串,求两个字符串中重复的子串,子串长度大于等于 3 (即设定 minimumTileSize 为 3 )。答案显而易见,是 ABCD 和 BCD ,但是在这个问题中, BCD 是要被丢弃的。
在这个例子中,tokens 为 EABCDEDA | IJABCDEFG。CPD 的想法是首先找到长度等于 3 的重复子串。假设有一排盒子,CPD 从文件末尾开始,每次将一个将长度为 3 的字符串存入盒子中,相同的字符串被放到同一个盒子中。
| EFG | DEF | CDE | BCD , BCD | ABC , ABC | JAB | IJA | EDA | DED | ...... |
CPD 使用 HashMap 作为这些“盒子”。由于完成两个字符串的比较需要对其中包含的字符进行逐个比较,所需的时间较长,而数值比较则一次就可以完成,所以将 CPD 将使用 Hash 值作为比较字符(Token)串的依据。将 A 、B 、C ... Z 分别标记为 0 、1 、2 ... 25,假设字符串长度为 n,令 M = 26 ,则可以使字符串的 Hash 值为
o
第 1 个字母的映射值 * M ^ (n-1) + 第 2 个字母的映射值 * M ^ (n-2) + ... + 第 n 个字母的映射值 * M ^ (n-n)
ABC 的 hash 值为 0 * 26 * 26 + 1 * 26 + 2
BCD 的 hash 值为 1 * 26 * 26 + 2 * 26 + 3
可以看到,将所有的不同的字符(Token)从 0 到 k 标记,只要 M >= k + 1 就可以保证不同的字符(Token)串有不同的 Hash 值。但是我们并不知道会有多少个字符(Token),并且 M 取一个很大的值会影响运算速度。 所以我们取一个合适的值(CPD 取的是 37 ,因为 z = 37 * x 可以拆分成 y = x + 8 * x ; z = x + 4 * y ,这两步都对应于一条 LEA x86 指令,计算较快),对于可能出现的 Hash 冲突,我们再进行进一步处理。
另外,CPD 使用 Rabin-Karp 算法克服朴素的字符串匹配算法“健忘”的缺点。前一次匹配的信息其实有部分可以应用到后一次匹配中去,而朴素的字符串匹配算法只是简单的把这个信息扔掉,从头再来,因此浪费了时间。 Rabin-Karp 算法利用了这些信息,提高运行速度。
例如在字符串 "ABCDE" 中查找 "CDE" , 朴素的字符串匹配算法会独立地计算三次检查的字符串的 Hash 值:
ABC 的 hash 值为 0 * 26 * 26 + 1 * 26 + 2 = value1
BCD 的 hash 值为 1 * 26 * 26 + 2 * 26 + 3 = value2
CDE 的 hash 值为 2 * 26 * 26 + 3 * 26 + 4 = value3
而 Rabin-Karp 算法则是在前一次匹配的基础上将被删除的字母的信息去掉,再加上新增的字母的信息:
ABC 的 hash 值为 0 * 26 * 26 + 1 * 26 + 2 = value1
BCD 的 hash 值为 (value1 - 0 * 26 * 26) * 26 + 3 = value2
CDE 的 hash 值为 (value2 - 1 * 26 * 26) * 26 + 4 = value3
当要匹配的字符串较长时,Rabin-Karp 算法可以利用前一次匹配的信息减少后一次匹配的计算量,运行速度会有非常明显的提升。
继续上面字符串匹配的例子,字符串匹配阶段结束后得到候选结果:
|EFG|DEF|CDE|EDA,BCD,BCD|ABC,ABC|JAB|IJA|DED|......|
经过了 Rabin-Karp 算法和 HashMap 的两次 Hash 之后,可能会发生 Hash 碰撞,例如图中的 EDA 和 BCD 在两次 Hash 后具有同样的 Hash 值。
5. 处理候选结果
CPD 对每个盒子中的子串两两比较:
- 子串具有相同的前导字母,如例子中的 BCD,BCD
- 子串相同的字母数小于指定的最小值,即发生了 Hash 碰撞,如例子中的 EDA,BCD
- 两个代码片段有重叠
排除了上述三种情况,CPD 会计算这些代码片段(Mark)实际重复的 Token 数量,并将重复 Token 数量的代码片段(Mark)放在同一个 Match 中,这时候就已经得到了准确的结果。
|ABCD,ABCD|
6. 结果展示
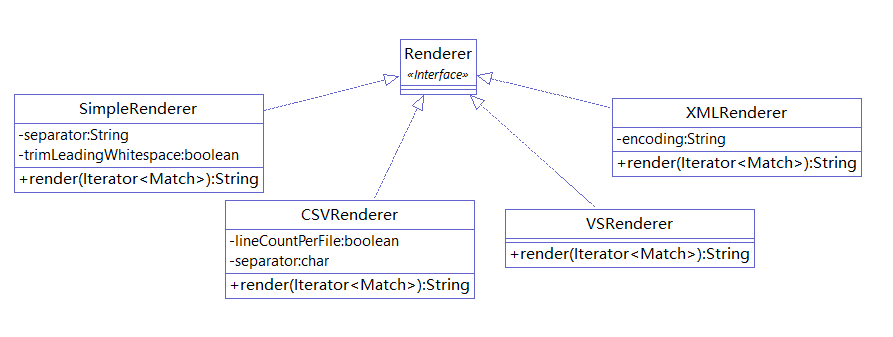
CPD 提供多种结果展示的方式,默认是使用 SimpleRenderer 将结果直接打印到控制台。
总结
本文介绍了 CPD 代码复制粘贴检测的原理,除了文中介绍的 Java 复制粘贴检测外,使用 Antlr 提供的语法描述文件,可以实现大多数编程语言的复制粘贴检测。本文介绍的方法可以进一步拓展到用于任意文本的复制粘贴检测。
评论
暂无评论,来发表第一条评论吧